ErogameScapeの現用系サーバーは、ここ1年ほど障害がなく動いていたため、待機系サーバーがトラヒックをさばくことはありませんでした。
待機系サーバーの動作チェックといえば、HDDが壊れるかもしれませんので、毎日muninのグラフを眺めたり、待機系サーバーにアクセスしてもちゃんとコンテンツが表示されることを確認したりするくらいでした。
さて、12月23日の15時頃、現用系のサーバーが温度異常で落ちました。
待機系サーバーに切り替わったまではよかったのですが、想定ですがErogameScapeにアクセスしても応答がない、または応答が著しく遅い状態になりました。
当時の/var/log/httpd/error.logです。
tmpwatchは、もちろんディレクトリごと消すので、現用系サーバーから定期的にファイルが送られてくる/tmp/createrは消えないですが、/tmp/indexや、/tmp/gameは10日で消えます。
トップページのPHPスクリプトは/tmp/indexにキャッシュを生成しようとしますが、/tmp/indexがないのでキャッシュを生成できず、いちいちDBにアクセスして応答を返す、応答を返すまで2秒くらい…という状況になっていたということです。
ああ、そら、駄目だ…
ということで、待機系サーバーにキャッシュ用のディレクトリを作りなおして、現用系サーバーのrsyncも設定し直して、現用系サーバーからrsyncして、めでたしめでたし…となると思ったのですが、 それでも状況はかわりませんでした。応答がすごく遅いです。
考えられる可能性は「キャッシュが読めてない」でした。
でも、キャッシュファイルは確かにあるだけどなあ…と思ってls -lで見ると、
のような出力でした。
現用系サーバーですと
です。
(1) なんで待機系サーバーのキッャシュファイルの権限がap2なんだっけ?
権限がapacheじゃなきゃキャッシュを更新できないじゃん
(2) もしかしてpearのCache_Liteは、キャッシュファィルの権限がapache(というかApacheで設定したユーザー)じゃないと読まない?
pearのCache_Liteを使う前は、実は自身で作ったキャッシュ機構を使っていて、そのキャッシュ機構は
・キャッシュの権限は666で生成する
だったので、誰でも読めるし更新もできるものでした。
なので、キャッシュを生成するユーザーは全然気にしていませんでした。
Cashe_Liteは644で、ユーザーはapacheで生成します。…正しいですね。
※ちなみに権限を変更するオプションはないので、権限をかえるならスクリプトの中でchownするなりする必要があるかなと。まあ…そんな必要はないかな…
644のapacheで生成されたファィルをrsyncで待機系サーバーに送っているのですが、rsyncで権限をそのままにコピーするには
で、root権限がないと駄目です。
私はそもそもそんなオプションつけてませんでした…オプションをつけるならつけたときにrootユーザーでrsyncのcronを設定していたと思いますし…
これで(1)は解決、(2)についてはちゃんと調べていないのですが、実際キャッシュファイルを読めていなかったので、まあそんなもんなんだろう…ということで、
あと一箇所設定ミスがありました。
ErogameScapeではApacheが応答を返さなかった場合に、httpdをrestartするcronを動かしています。
以下のようなスクリプトです。
これを動かすcrontabは
*/2 * * * * /root/httpd_restart.sh
な感じなのですが、当時どうしてそうなっていたのか分からないのですが、
*/2 * * * * chmod 700 /root/httpd_restart.sh
になっていました。
意味がわかりません…
また、上記スクリプトのwgetは当時
wget -nv -S --spider -t 2 -T 5 http://127.0.0.1/~ap2/
としていました。
httpdの応答だから、これでいいかなと思っていたのですが、サービス監視としてはトップページである
http://127.0.0.1/~ap2/ero/toukei_kaiseki/
の応答を見るのが正しいなということで、変更しました。
以上が、12月23日~24日にかけて繋がりにくかった件の顛末です。
1年以上障害がなかったので、待機系サーバーが使い物になっていないことに全然気がつきませんでした。
これからはたまに待機系サーバーに首をふってみようと思います。
大変ご迷惑をおかけいたしました。
今後ともよろしくお願いいたします。
待機系サーバーの動作チェックといえば、HDDが壊れるかもしれませんので、毎日muninのグラフを眺めたり、待機系サーバーにアクセスしてもちゃんとコンテンツが表示されることを確認したりするくらいでした。
さて、12月23日の15時頃、現用系のサーバーが温度異常で落ちました。
待機系サーバーに切り替わったまではよかったのですが、想定ですがErogameScapeにアクセスしても応答がない、または応答が著しく遅い状態になりました。
当時の/var/log/httpd/error.logです。
/var/log/httpd/error_log
[Sat Dec 22 15:10:34 2012] [error] server reached MaxClients setting, consider raising the MaxClients setting
[Sat Dec 22 15:10:48 2012] [error] [client 49.251.60.176] PHP Warning: pg_connect(): Unable to connect to PostgreSQL server: could not connect to server: Connection refused
Is the server running on host "localhost" and accepting
TCP/IP connections on port 9999?
(1) server reached MaxClients settingについて
ErogameScaeのApacheはprefork MPMで動かしています。
※何かのドキュメントを読んだ結果、prefork MPMより、worker MPMの方がよさそうだな…と思った記憶があるのですが、そのままでも問題なく動いているので、何も検討せずprefork MPMで動かしています。
prefork MPMには、 MaxClientsという設定があります。
MaxClientsは同時接続数の上限を決める値で、ErogameScapeでは200としています。
この上限を超えた接続があると、ErogameScapeの場合、ユーザーさんから見て応答がなくなります。
Apacheの再起動をしないと回復しません。
第2回 コネクション受付制御のパラメータ | Think ITやApacheのMaxClientsの設定とその挙動をまとめてみた | SUEKICHI.orgを読むと、待っていればキューにたまっているものは処理され、キューを超えた接続はRejectされ、Apacheからずっと応答が返ってこないことはなさそうなのですが、Apacheの再起動をしないと回復しません。topコマンドの出力を眺めていると、最初はLoad Averageが異様に高いのですが、server reached MaxClients setting, consider raising the MaxClients settingのメッセージを吐いた後は、だんだんとLoad Averageが少なくなっていき、0以下になるけども、いつまでたってもApacheは応答を返してくれないという状況です。
多分、Apacheとpgpoolの間のやりとりがつまっているからだと想定するのですがよくわかりません。
(2) Unable to connect to PostgreSQL serverについて
ErogameScapeはPostgreSQLを使用しています。またApacheとPostgreSQLの間にpgpool-IIを使用しています。pgpoolにも同時接続数の上限を設定できるパラメータとしてnum_init_childrenがあります。
ErogameScapeでは、num_init_childrenを100に設定しています。
num_init_childrenの説明は以下の通りです。
ApacheのMaxClientsが200なので、最大で200の要求がpgpoolにきますが、Apacheはキャッシュを返すことが多いのと、実際200の接続も来ない(下図参照、Apacheのbusy serversは100以下におさまっています。)ので、num_init_childrenを100で問題ありませんでした。
が… Unable to connect to PostgreSQL serverというメッセージが出たということは、接続上限の100を超えた接続が継続した結果、pgpoolに接続できなかったということです。
さて…
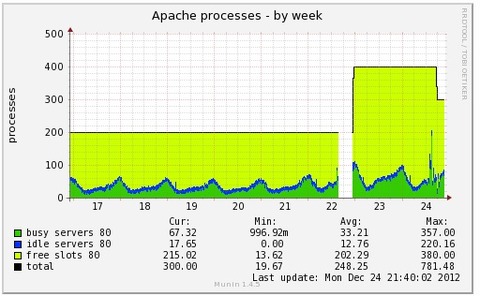
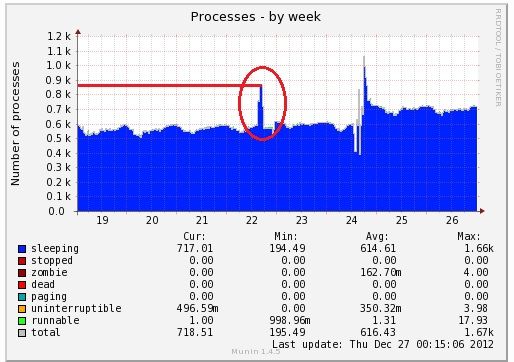
MaxClients setting, consider raising the MaxClients settingが出た理由はなんだろう?と思って、待機系のサーバーの当時のApacheのprocessのmuninのグラフを見たら
となっていました。赤丸の部分が現用のサーバーが落ちた時刻です。
MaxClientsの設定が今までなぜか100になっていました。
サーバーを設定するためのテキストファイルを見たら、確かに100と書いてありました…
設定ミスです。100でも平常時は足りるのですが、サーバーを再起動したり、サーバーが長時間落ちていて復旧させると、ユーザーさんがいっせいにアクセスして一時的に100を超えることがあります。
この設定を修正しました。
※ちなみに1年以上前から設定をミスっていました…
修正後の値はなんとなくで400にしました。
というのは、もともとの設定は200なのですが、一時的なアクセスが200を超えて、Apacheの応答がなくなって再起動が必要なことがときどきあるので、ざっくり400にしておくかーと思ったからでした。
PostgrsqlSQLに必要なmax_connections(同時接続数)は、
pgpoolに接続するユーザーの数 × IPアドレス × pgpoolのnum_init_children
で計算できます。
現用系サーバーだけが動いている場合、権限が違う3つのユーザー × 2アドレス × 100 = 600 となります。
PostgrsqlSQLのmax_connectionsは1000に設定しているので問題ないと思っていました。
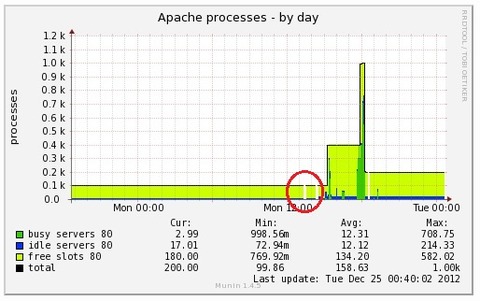
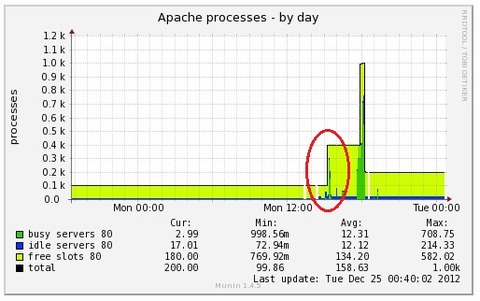
待機系サーバーに切り替わったときにProcessが200ほど増えました。
これを見て、当時の自分は「現用系サーバーのApacheからpgpoolへの接続が持ちきっていて解放できていなくて、これに待機系サーバーのApacheからpgpooへlの接続(600くらい)が加わって800程度になったのかな」と勘違いしました。その結果、PostgrsqlSQLのmax_connectionsは1000だけど、一時的に1000を超えた接続があって、結果、Unable to connect to PostgreSQL serverになったのかなと思いました。
※pgpool (ポート9999)への接続ができていなかったので、PostgrsqlSQLのmax_connectionsは関係ないのですが…
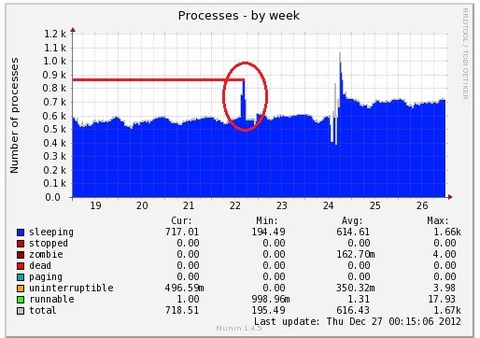
その後、勘違いに気がついて、pgpoolのnum_init_childrenを倍にして、待機系サーバーに再度首をふった結果が以下のグラフの赤丸の部分です。
待機系サーバーで
tail -f /var/log/httpd/error_log
を実行しておきつつ、現用系サーバーでkeepalivedを停止して待機系サーバーに首をふりました。
数分もしないうちに、
server reached MaxClients setting
Unable to connect to PostgreSQL server
を吐いて応答がなくなりました…
その後、MaxClients settingを1000まで増やしてみて、首をふりましたが、同じように数分で応答がなくなりました。
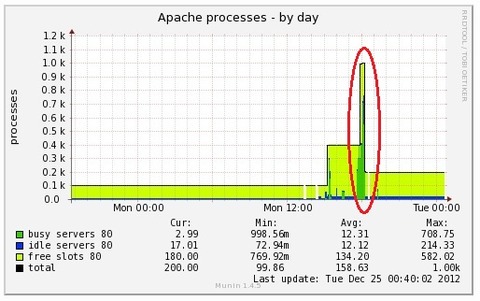
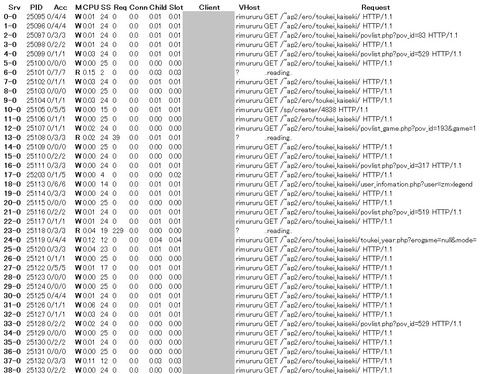
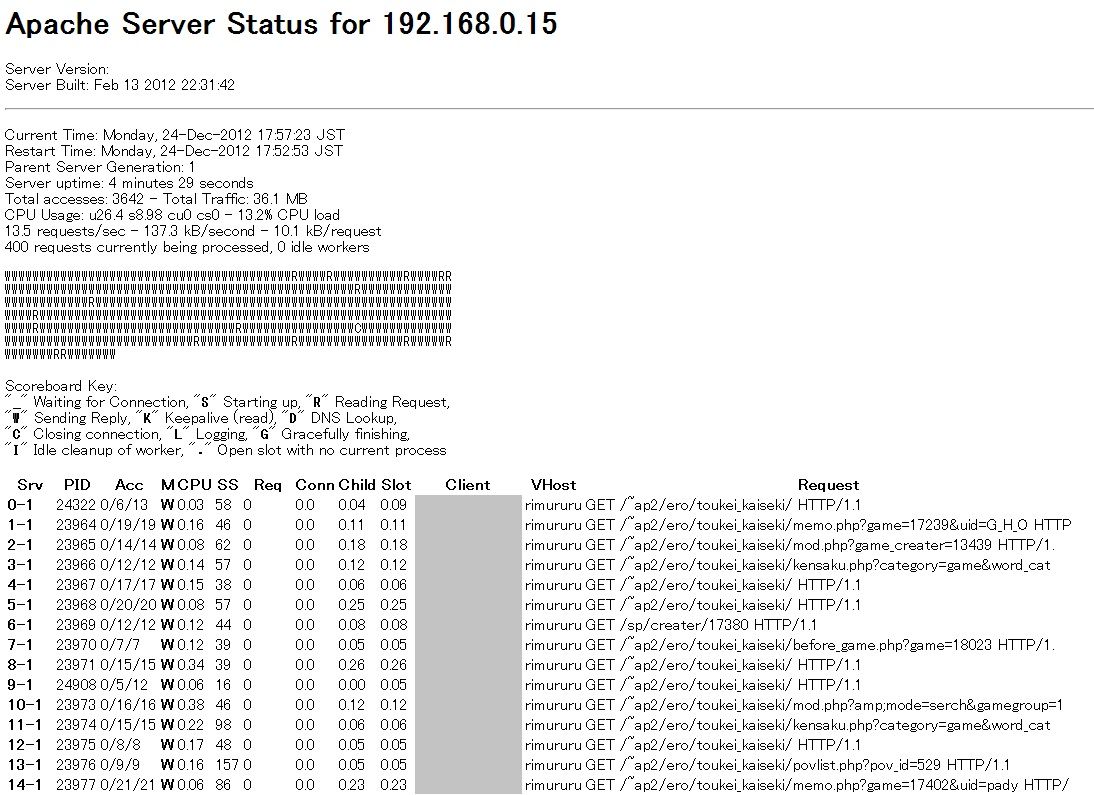
MaxClients settingを400にした際のApache Server Statusを抜粋します。
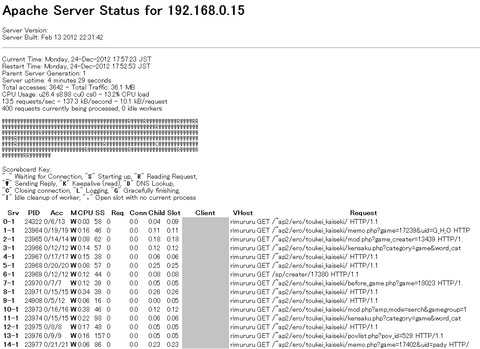
みるみるうちにrequestsが400に、はりつきます。
Apache Server Statusを見てあれ?と思ったのが、トップページへのアクセス「/~ap2/ero/toukei_kaiseki/」のRequestが多くて(多いのは確かにそうなのですが)"W" Sending Replyの状態だということでした。
(1) server reached MaxClients settingについて
ErogameScaeのApacheはprefork MPMで動かしています。
※何かのドキュメントを読んだ結果、prefork MPMより、worker MPMの方がよさそうだな…と思った記憶があるのですが、そのままでも問題なく動いているので、何も検討せずprefork MPMで動かしています。
prefork MPMには、 MaxClientsという設定があります。
MaxClientsは同時接続数の上限を決める値で、ErogameScapeでは200としています。
この上限を超えた接続があると、ErogameScapeの場合、ユーザーさんから見て応答がなくなります。
Apacheの再起動をしないと回復しません。
第2回 コネクション受付制御のパラメータ | Think ITやApacheのMaxClientsの設定とその挙動をまとめてみた | SUEKICHI.orgを読むと、待っていればキューにたまっているものは処理され、キューを超えた接続はRejectされ、Apacheからずっと応答が返ってこないことはなさそうなのですが、Apacheの再起動をしないと回復しません。topコマンドの出力を眺めていると、最初はLoad Averageが異様に高いのですが、server reached MaxClients setting, consider raising the MaxClients settingのメッセージを吐いた後は、だんだんとLoad Averageが少なくなっていき、0以下になるけども、いつまでたってもApacheは応答を返してくれないという状況です。
多分、Apacheとpgpoolの間のやりとりがつまっているからだと想定するのですがよくわかりません。
(2) Unable to connect to PostgreSQL serverについて
ErogameScapeはPostgreSQLを使用しています。またApacheとPostgreSQLの間にpgpool-IIを使用しています。pgpoolにも同時接続数の上限を設定できるパラメータとしてnum_init_childrenがあります。
ErogameScapeでは、num_init_childrenを100に設定しています。
num_init_childrenの説明は以下の通りです。
preforkするpgpool-IIのサーバプロセスの数です。デフォルト値は32になっています。 これが、pgpool-IIに対してクライアントが同時に接続できる上限の数になります。 これを超えた場合は、そのクライアントは、pgpool-IIのどれからのプロセスへのフロントエンドの接続が終了するまで 待たされます(PostgreSQLと違ってエラーになりません)。 待たされる数の上限は、2 * num_init_children です。
ApacheのMaxClientsが200なので、最大で200の要求がpgpoolにきますが、Apacheはキャッシュを返すことが多いのと、実際200の接続も来ない(下図参照、Apacheのbusy serversは100以下におさまっています。)ので、num_init_childrenを100で問題ありませんでした。

が… Unable to connect to PostgreSQL serverというメッセージが出たということは、接続上限の100を超えた接続が継続した結果、pgpoolに接続できなかったということです。
さて…
MaxClients setting, consider raising the MaxClients settingが出た理由はなんだろう?と思って、待機系のサーバーの当時のApacheのprocessのmuninのグラフを見たら
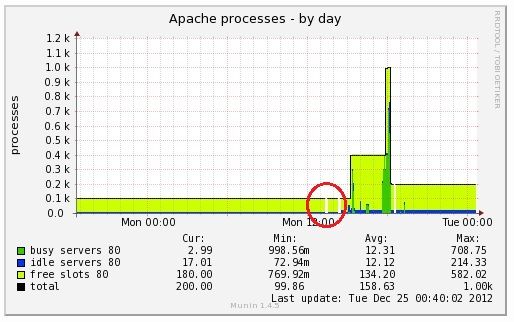
となっていました。赤丸の部分が現用のサーバーが落ちた時刻です。
MaxClientsの設定が今までなぜか100になっていました。
サーバーを設定するためのテキストファイルを見たら、確かに100と書いてありました…
設定ミスです。100でも平常時は足りるのですが、サーバーを再起動したり、サーバーが長時間落ちていて復旧させると、ユーザーさんがいっせいにアクセスして一時的に100を超えることがあります。
この設定を修正しました。
※ちなみに1年以上前から設定をミスっていました…
修正後の値はなんとなくで400にしました。
というのは、もともとの設定は200なのですが、一時的なアクセスが200を超えて、Apacheの応答がなくなって再起動が必要なことがときどきあるので、ざっくり400にしておくかーと思ったからでした。
PHP Warning: pg_connect(): Unable to connect to PostgreSQL server: could not connect to server: Connection refused
Is the server running on host "localhost" and accepting
TCP/IP connections on port 9999?
については、 この時点でどうしてpgpool(ポートは9999)に接続できないかさっぱりわかりませんでした。PostgrsqlSQLに必要なmax_connections(同時接続数)は、
pgpoolに接続するユーザーの数 × IPアドレス × pgpoolのnum_init_children
で計算できます。
現用系サーバーだけが動いている場合、権限が違う3つのユーザー × 2アドレス × 100 = 600 となります。
PostgrsqlSQLのmax_connectionsは1000に設定しているので問題ないと思っていました。
待機系サーバーに切り替わったときにProcessが200ほど増えました。
これを見て、当時の自分は「現用系サーバーのApacheからpgpoolへの接続が持ちきっていて解放できていなくて、これに待機系サーバーのApacheからpgpooへlの接続(600くらい)が加わって800程度になったのかな」と勘違いしました。その結果、PostgrsqlSQLのmax_connectionsは1000だけど、一時的に1000を超えた接続があって、結果、Unable to connect to PostgreSQL serverになったのかなと思いました。
※pgpool (ポート9999)への接続ができていなかったので、PostgrsqlSQLのmax_connectionsは関係ないのですが…
その後、勘違いに気がついて、pgpoolのnum_init_childrenを倍にして、待機系サーバーに再度首をふった結果が以下のグラフの赤丸の部分です。
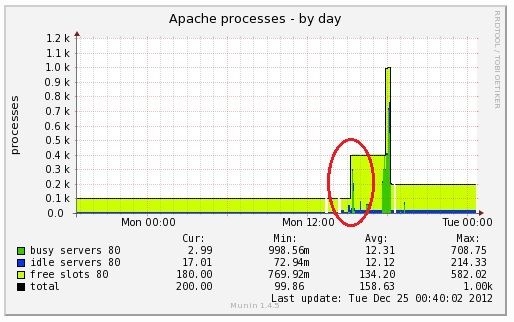
待機系サーバーで
tail -f /var/log/httpd/error_log
を実行しておきつつ、現用系サーバーでkeepalivedを停止して待機系サーバーに首をふりました。
数分もしないうちに、
server reached MaxClients setting
Unable to connect to PostgreSQL server
を吐いて応答がなくなりました…
その後、MaxClients settingを1000まで増やしてみて、首をふりましたが、同じように数分で応答がなくなりました。
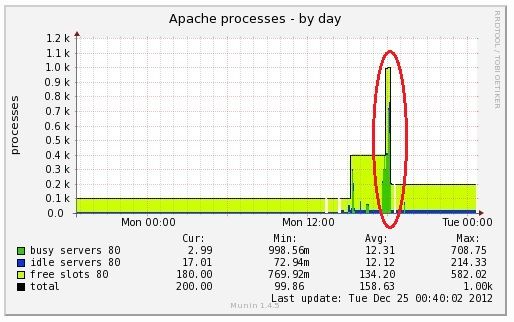
MaxClients settingを400にした際のApache Server Statusを抜粋します。
みるみるうちにrequestsが400に、はりつきます。
Apache Server Statusを見てあれ?と思ったのが、トップページへのアクセス「/~ap2/ero/toukei_kaiseki/」のRequestが多くて(多いのは確かにそうなのですが)"W" Sending Replyの状態だということでした。

トップページはDBに接続しますが、ほとんどキャッシュなので二桁ms単位で応答を返すはずでした。
下に現在のトップページの応答時間の画像を示します。

画像を保存するのを忘れてはれないのですが、当時、待機系サーバーのトップページの応答時間は秒単位で話にならないレベルでした。
考えられる原因は「キャッシュがきいてない」です。
ErogameScapeでは、キャッシュにpearのCache_Liteを使っています。
キャッシュの保存先は/tmpです。 ← 問題1
また、待機系サーバーはいつもはアクセスがないので、キャッシュを生成しないことから、現用系サーバーから待機系サーバーにキャッシュをrsyncでコピーしています。 ← 問題2
トップページ系のキャッシュなら/tmp/index、game.php系のキャッシュなら/tmp/gameのようにディレクトリを作って、キャッシュを格納しています。
※ディレクトリをわけているのは、game.php更新して実は不具合があってキャッシュを消したいといった場合に便利だからです。キャッシュされるファィル名はハッシュ値なので、ファィル名からどのスクリプトが生成したキャッシュかを判別するのが困難です。
ちなみにキャッシュファイル名は以下のような感じです。
待機系サーバーの/tmpを確認すると、/tmp/indexがありませんでした。
また、/tmp/gameもありませんでした。
/tmp/creater(creater.php系のキャッシュを格納するディレクトリ)はありました。
さて…なんでこんなことになるのか…と思って、現用系サーバーのcronで定期的に実行している現用系サーバーから待機系サーバーへの/tmp配下のrsyncを見たら、/tmp/createrはrsyncしていますが、/tmp/indexや/tmp/gameはrsyncしていませんでした。
そういえば、/tmpの配下のファイルって消えるんだっけ、でもいつ消えるんだっけ?ということでgoogle先生に聞くと、@IT:/tmpのファイルがいつの間にか消えてしまうということで、tmpwatchに書いてあるとのことです。
CentOS6のtmpwatchは以下の通りでした。
下に現在のトップページの応答時間の画像を示します。
画像を保存するのを忘れてはれないのですが、当時、待機系サーバーのトップページの応答時間は秒単位で話にならないレベルでした。
考えられる原因は「キャッシュがきいてない」です。
ErogameScapeでは、キャッシュにpearのCache_Liteを使っています。
キャッシュの保存先は/tmpです。 ← 問題1
また、待機系サーバーはいつもはアクセスがないので、キャッシュを生成しないことから、現用系サーバーから待機系サーバーにキャッシュをrsyncでコピーしています。 ← 問題2
トップページ系のキャッシュなら/tmp/index、game.php系のキャッシュなら/tmp/gameのようにディレクトリを作って、キャッシュを格納しています。
※ディレクトリをわけているのは、game.php更新して実は不具合があってキャッシュを消したいといった場合に便利だからです。キャッシュされるファィル名はハッシュ値なので、ファィル名からどのスクリプトが生成したキャッシュかを判別するのが困難です。
ちなみにキャッシュファイル名は以下のような感じです。
[ap2@erogamescape14 sp]$ ls
cache_c21f969b5f03d33d43e04f8f136e7682_4b718b3868bd9361022eec6491d5c02d
cache_c21f969b5f03d33d43e04f8f136e7682_5943dbe6e144efe5d2b21e5f882df3ec
cache_c21f969b5f03d33d43e04f8f136e7682_6d05f0548144b97eb2f926aea9e4d0e7
cache_c21f969b5f03d33d43e04f8f136e7682_b07d4fb600552c8660de41e194707769
cache_c21f969b5f03d33d43e04f8f136e7682_b1fab48509ba289b67257d0572effbe3
cache_c21f969b5f03d33d43e04f8f136e7682_bdce208ad887e2ca02902c416e2bb0ba
待機系サーバーの/tmpを確認すると、/tmp/indexがありませんでした。
また、/tmp/gameもありませんでした。
/tmp/creater(creater.php系のキャッシュを格納するディレクトリ)はありました。
さて…なんでこんなことになるのか…と思って、現用系サーバーのcronで定期的に実行している現用系サーバーから待機系サーバーへの/tmp配下のrsyncを見たら、/tmp/createrはrsyncしていますが、/tmp/indexや/tmp/gameはrsyncしていませんでした。
そういえば、/tmpの配下のファイルって消えるんだっけ、でもいつ消えるんだっけ?ということでgoogle先生に聞くと、@IT:/tmpのファイルがいつの間にか消えてしまうということで、tmpwatchに書いてあるとのことです。
CentOS6のtmpwatchは以下の通りでした。
#! /bin/sh
flags=-umc
/usr/sbin/tmpwatch "$flags" -x /tmp/.X11-unix -x /tmp/.XIM-unix \
-x /tmp/.font-unix -x /tmp/.ICE-unix -x /tmp/.Test-unix \
-X '/tmp/hsperfdata_*' 10d /tmp
/usr/sbin/tmpwatch "$flags" 30d /var/tmp
for d in /var/{cache/man,catman}/{cat?,X11R6/cat?,local/cat?}; do
if [ -d "$d" ]; then
/usr/sbin/tmpwatch "$flags" -f 30d "$d"
fi
done
10日で消えます。tmpwatchは、もちろんディレクトリごと消すので、現用系サーバーから定期的にファイルが送られてくる/tmp/createrは消えないですが、/tmp/indexや、/tmp/gameは10日で消えます。
トップページのPHPスクリプトは/tmp/indexにキャッシュを生成しようとしますが、/tmp/indexがないのでキャッシュを生成できず、いちいちDBにアクセスして応答を返す、応答を返すまで2秒くらい…という状況になっていたということです。
ああ、そら、駄目だ…
ということで、待機系サーバーにキャッシュ用のディレクトリを作りなおして、現用系サーバーのrsyncも設定し直して、現用系サーバーからrsyncして、めでたしめでたし…となると思ったのですが、 それでも状況はかわりませんでした。応答がすごく遅いです。
考えられる可能性は「キャッシュが読めてない」でした。
でも、キャッシュファイルは確かにあるだけどなあ…と思ってls -lで見ると、
[ap2@erogamescape15 brand]$ ls -l
合計 8
-rw-r--r-- 1 ap2 ap2 4226 12月 24 19:20 2012 cache_c21f969b5f03d33d43e04f8f136e7682_dc23d669a5a1fd3a31f1472f9a7458b7
のような出力でした。
現用系サーバーですと
[ap2@erogamescape14 brand]$ ls -l
合計 8
-rw-r--r-- 1 apache apache 4226 12月 24 19:20 2012 cache_c21f969b5f03d33d43e04f8f136e7682_dc23d669a5a1fd3a31f1472f9a7458b7
です。
(1) なんで待機系サーバーのキッャシュファイルの権限がap2なんだっけ?
権限がapacheじゃなきゃキャッシュを更新できないじゃん
(2) もしかしてpearのCache_Liteは、キャッシュファィルの権限がapache(というかApacheで設定したユーザー)じゃないと読まない?
pearのCache_Liteを使う前は、実は自身で作ったキャッシュ機構を使っていて、そのキャッシュ機構は
・キャッシュの権限は666で生成する
だったので、誰でも読めるし更新もできるものでした。
なので、キャッシュを生成するユーザーは全然気にしていませんでした。
Cashe_Liteは644で、ユーザーはapacheで生成します。…正しいですね。
※ちなみに権限を変更するオプションはないので、権限をかえるならスクリプトの中でchownするなりする必要があるかなと。まあ…そんな必要はないかな…
644のapacheで生成されたファィルをrsyncで待機系サーバーに送っているのですが、rsyncで権限をそのままにコピーするには
[ap2@erogamescape15 ~]$ rsync --help | grep owner
-o, --owner preserve owner (super-user only)
で、root権限がないと駄目です。
私はそもそもそんなオプションつけてませんでした…オプションをつけるならつけたときにrootユーザーでrsyncのcronを設定していたと思いますし…
これで(1)は解決、(2)についてはちゃんと調べていないのですが、実際キャッシュファイルを読めていなかったので、まあそんなもんなんだろう…ということで、
- /tmp配下のキャッシュファィルを削除
- キャッシュに必要なディレクトリだけ作成
- 現用系サーバーからのrsyncをストップ
- tmpwatchの設定を変更してとりあえず1年は/tmp配下のファィルを消さないように修正
あと一箇所設定ミスがありました。
ErogameScapeではApacheが応答を返さなかった場合に、httpdをrestartするcronを動かしています。
以下のようなスクリプトです。
[root@erogamescape15 ~]# cat httpd_restart.sh
check=`wget -nv -S --spider -t 2 -T 5 http://127.0.0.1/~ap2/ero/toukei_kaiseki/ 2>&1|grep -c "200 OK"`
if [ $check != 2 ]
then
echo 'NG'
RESULT=`/sbin/service httpd restart`
`date >> httpd_restart_date.txt`
else
echo 'OK'
fi
これを動かすcrontabは
*/2 * * * * /root/httpd_restart.sh
な感じなのですが、当時どうしてそうなっていたのか分からないのですが、
*/2 * * * * chmod 700 /root/httpd_restart.sh
になっていました。
意味がわかりません…
また、上記スクリプトのwgetは当時
wget -nv -S --spider -t 2 -T 5 http://127.0.0.1/~ap2/
としていました。
httpdの応答だから、これでいいかなと思っていたのですが、サービス監視としてはトップページである
http://127.0.0.1/~ap2/ero/toukei_kaiseki/
の応答を見るのが正しいなということで、変更しました。
以上が、12月23日~24日にかけて繋がりにくかった件の顛末です。
1年以上障害がなかったので、待機系サーバーが使い物になっていないことに全然気がつきませんでした。
これからはたまに待機系サーバーに首をふってみようと思います。
大変ご迷惑をおかけいたしました。
今後ともよろしくお願いいたします。
